Writing distributed applications is very hard, especially when you start developing them as single-noded ones. Programmers tend to focus on functionalities first, leaving the scalability issues for later. Fortunately, Akka gives us many tools for scaling out and we can use them very early in the development process. You will learn how to take advantage of these features by transforming single-noded non-scalable web service into a scalable one.
Our case: The Conveyor Junction Web Service
Imagine we want to write a web service that is called each time a container appears on the junction of the conveyor.

This web service is going to define one endpoint, which will be hit each time a container is scanned before the junction. The endpoint should return an id of the target conveyor. The container will be then pushed onto target conveyor by the hardware.
GET /junctions/<junctionId>/decisionForContainer/<containerId> returns
{
"targetConveyor": "<conveyorId>"
}
Before we start implementation, I’d like to point out some assumptions:
- we use simple
Containerobjects with id only (persistence layer can be added later). - we use simple
Junctionobjects (same story), - business logic is already defined in the
whereShouldContainerGofunction which returns the decision for aContaineron theJunctionpassed as one of the parameters - the call to this function takes about 5-10 ms.
We need to implement an HTTP Service which uses the business logic function. We will not focus on the functionality (hence above assumptions), but the performance and scalability. The only functional requirement that matters is that for each junction the decisions should be made sequentially in the order of scanned containers.
You can implement the same service and do the same performance analysis as you read the article by checking out akka-sharding-example repository on GitHub. Each step in this blog post has a corresponding branch in the repository to make your life easier.
We will use Akka
We will use plain Akka, no additional extensions, especially no clustering (yet). Just simple app running on one JVM. I want to show that even without thinking about scalability at the beginning, it is still reasonably easy to add it later.
Step 0: Defining domain and internal API
Let’s define what language our components (actors) will use to communicate and how our domain will be modeled. This can be easily represented using Scala case classes:
object Domain {
case class Junction(id: Int)
case class Container(id: Int)
}
We have only two domain objects. One represents a Junction, the other one represents a Container.
Our service won’t receive any JSON data, it will just return JSON object: Go(targetConveyor). It will be automatically marshaled into JSON thanks to the implicit default conversion defined in its companion object:
object Messages {
case class Go(targetConveyor: String)
object Go {
implicit val goJson = jsonFormat1(Go.apply)
}
}
Step 1: Creating REST Interface layer
Now it’s time to code something real. To implement the HTTP service we will use spray-http with spray-json. Our service will only define one endpoint and, based on the passed parameters, it will call our business logic function and return the result wrapped in Go object.
class RestInterface(exposedPort: Int) extends Actor with HttpServiceBase with ActorLogging {
val route: Route = {
path("junctions" / IntNumber / "decisionForContainer" / IntNumber) { (junctionId, containerId) =>
get {
complete {
log.info(s"Request for junction $junctionId and container $containerId")
val junction = Junction(junctionId)
val container = Container(containerId)
val decision = Decisions.whereShouldContainerGo(junction, container)
Go(decision)
}
}
}
}
def receive = runRoute(route)
implicit val system = context.system
IO(Http) ! Http.Bind(self, interface = "0.0.0.0", port = exposedPort)
}
I defined an actor which would be handling HTTP Requests. Inside this actor I created a route which is constructed from nested Directives.
pathdirective applies the givenPathMatcherto the HTTP request path and after successful matching, passes the request to its nested route. Additionally, it extracts two values from the path,junctionIdandcontainerId.getdirective makes sure onlyHTTP GETmethod requests are passed into its nested routes.completedirective accepts a marshallable object and returns it as HTTP response. In this case I don’t use any blocking operations and returnFuture[Go]as my object. The real response will be returned when thisFuturecompletes.
Right now we have almost everything we need to do our first test run. The only missing bit is the entry point for the application.
object SingleNodeApp extends App {
implicit val system = ActorSystem("sorter")
system.actorOf(RestInterface.props(8080))
}
Let’s run this application and see how it works.
± % http localhost:8080/junctions/2/decisionForContainer/3
HTTP/1.1 200 OK
Content-Length: 36
Content-Type: application/json; charset=UTF-8
Date: Sat, 10 Oct 2015 23:18:12 GMT
Server: spray-can/1.3.3
{
"targetConveyor": "CVR_2_9288"
}
We see that after scanning container #3 on junction #2, our service made a decision to push the container onto conveyor CVR_2_9288. The current architecture looks like this:
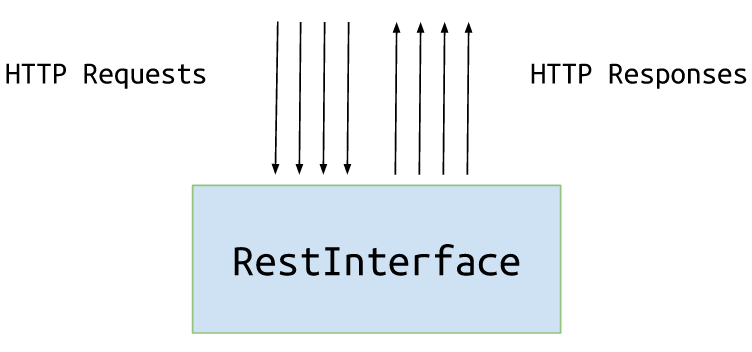
Performance testing
Let’s simulate 10000 calls of our web service, checking the decision for 5 junctions. We will use ab (ApacheBench) and parallel (GNU Parallel). For each junction we will simulate a sequence of calls (using ab). The parallelisation will kick in on the web service level. We will use parallel in order to make parallel calls for 5 different junctions.
Note about performance testing on a laptop
Remember that numbers presented in this section may (and will) differ depending on a machine, OS, running apps, network, etc. But for the purpose of this post, they are sufficient.
Note about constraining Akka
In order for all of our tests to be meaningful we will need to constraint Akka. I am using a 4-core processor. For each running Actor System, we will constraint the parallelism of its default MessageDispatcher to 2. This will allow us to simulate a service which struggles to get resources.
actor {
provider = "akka.cluster.ClusterActorRefProvider"
# capping default-dispatcher for demonstration purposes
default-dispatcher {
fork-join-executor {
# Max number of threads to cap factor-based parallelism number to
parallelism-max = 2
}
}
}
Testing our first implementation
Now it’s time to test what we currently have.
URLs.txt:
http://127.0.0.1:8080/junctions/1/decisionForContainer/1
http://127.0.0.1:8080/junctions/2/decisionForContainer/4
http://127.0.0.1:8080/junctions/3/decisionForContainer/5
http://127.0.0.1:8080/junctions/4/decisionForContainer/2
http://127.0.0.1:8080/junctions/5/decisionForContainer/7
± % cat URLs.txt | parallel -j 5 'ab -ql -n 2000 -c 1 -k {}' | grep 'Requests per second'
Requests per second: 34.78 [#/sec] (mean)
Requests per second: 34.22 [#/sec] (mean)
Requests per second: 33.77 [#/sec] (mean)
Requests per second: 33.82 [#/sec] (mean)
Requests per second: 33.98 [#/sec] (mean)
We defined our 5 URLs (one for each junction) to be called in parallel, and each of them:
- 2000 times (
-n 2000), - at most 1 at one time (
-c 1), - and using keep-alive (
-k).
We are only interested in Requests per second. As you see, the throughput of our service is around 34 requests per second. Let’s put it into perspective by introducing one actor per junction.
Step 2: One actor per junction
We just have one actor (= one thread) that sequentially makes a decision for all junctions. We know we can do better by trying to process junctions in parallel (because they are independent).
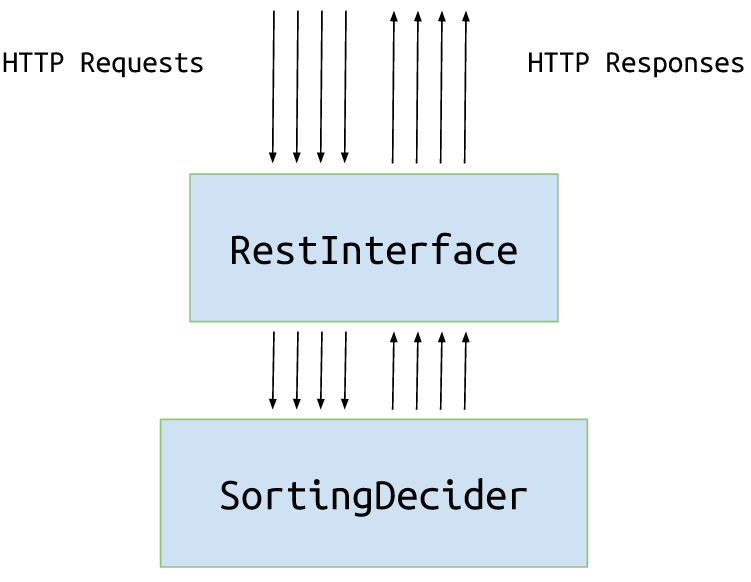
Firstly let’s add a new message to our Messages.
object Messages {
case class WhereShouldIGo(junction: Junction, container: Container)
// ...
}
The message WhereShouldIGo will be sent to the actor responsible for making a decision.
The decider actor will be very simple. It should be able to receive message WhereShouldIGo and reply with Go based on the logic that we have in the whereShouldContainerGo function.
class SortingDecider extends Actor with ActorLogging {
def receive: Receive = {
case WhereShouldIGo(junction, container) => {
val targetConveyor = Decisions.whereShouldContainerGo(junction, container)
sender ! Go(targetConveyor)
}
}
}
Now we need to modify our RestInterface to take one decider actor as dependency and use it whenever a decision needs to be made.
class RestInterface(decider: ActorRef, exposedPort: Int) extends Actor with HttpServiceBase with ActorLogging {
val route: Route = {
path("junctions" / IntNumber / "decisionForContainer" / IntNumber) { (junctionId, containerId) =>
get {
complete {
log.info(s"Request for junction $junctionId and container $containerId")
val junction = Junction(junctionId)
val container = Container(containerId)
decider.ask(WhereShouldIGo(junction, container))(5 seconds).mapTo[Go]
}
}
}
}
// ...
}
Let’s pass this actor to our RestInterface during construction phase.
object SingleNodeApp extends App {
implicit val system = ActorSystem("sorter")
val decider = system.actorOf(Props[SortingDecider])
system.actorOf(Props(classOf[RestInterface], decider, 8080))
}
What have we gained by introducing the actor to just wrap a function call? Let’s check.
± % cat URLs.txt | parallel -j 5 'ab -ql -n 2000 -c 1 -k {}' | grep 'Requests per second'
Requests per second: 34.49 [#/sec] (mean)
Requests per second: 34.49 [#/sec] (mean)
Requests per second: 34.49 [#/sec] (mean)
Requests per second: 34.50 [#/sec] (mean)
Requests per second: 34.52 [#/sec] (mean)
Nothing, we gained nothing. Our code is still sequential and we added yet another layer of abstraction. But we are not done yet.
Step 3: One actor per junction + routing
We need to create another layer: an actor that will create SortingDeciders per junction and proxy WhereShouldIGo messages to the right ones. This way our system will make decisions in parallel.
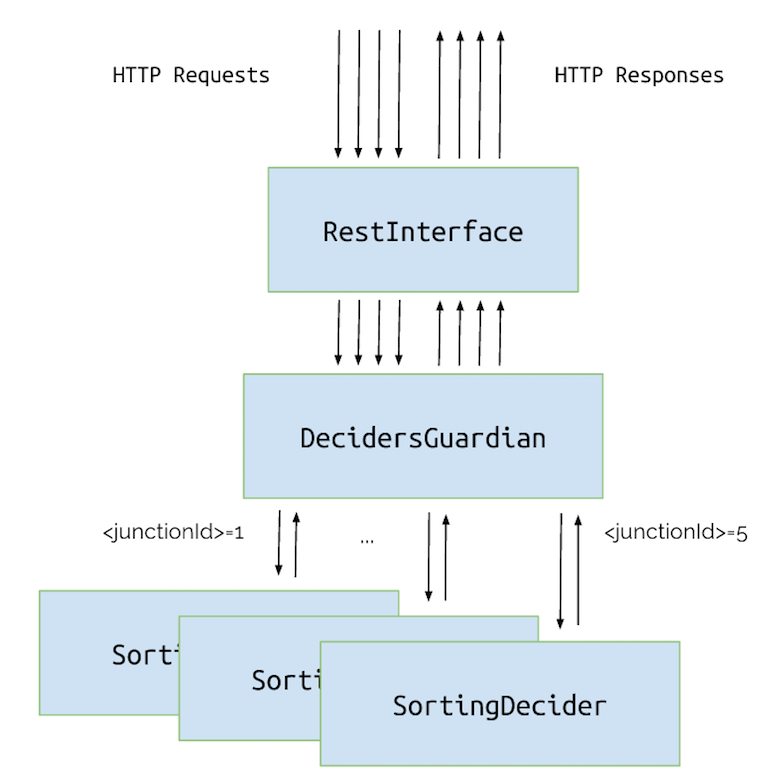
class DecidersGuardian extends Actor {
def receive = {
case m: WhereShouldIGo =>
val name = s"J${m.junction.id}"
val actor = context.child(name) getOrElse context.actorOf(Props[SortingDecider], name)
actor forward m
}
}
Let’s add our new DecidersGuardian actor as a dependency for RestInterface:
object SingleNodeApp extends App {
implicit val system = ActorSystem("sorter")
val decider = system.actorOf(Props[DecidersGuardian])
system.actorOf(Props(classOf[RestInterface], decider, 8080))
}
Right now, when our RestInterface gets 2 messages for different junctions, it will forward them to two different actors and they will be able to make decisions in parallel. Therefore, we should get a substantial improvement:
± % cat URLs.txt | parallel -j 5 'ab -ql -n 2000 -c 1 -k {}' | grep 'Requests per second'
Requests per second: 67.36 [#/sec] (mean)
Requests per second: 69.03 [#/sec] (mean)
Requests per second: 67.75 [#/sec] (mean)
Requests per second: 66.88 [#/sec] (mean)
Requests per second: 66.28 [#/sec] (mean)
Scalability testing
Until now, we have been concerned only about the performance of our service. Performance is how fast something can be done in terms of time. Requests per second metric that we have been using so far is a good example. So what’s the difference between performance and scalability?
Scalability of a system is how adding more resources affects its performance. E.g. doubling the throughput by doubling the resources is linear scalability. In our example, when we add more CPUs, we should be able to scale thanks to the Akka and actor model. This approach is called scaling up. What about scaling out, i.e. adding more computers to improve the performance?
Step 4: Making our web service scalable
We can scale out by adding more computers (or JVMs) and run our app on each of them. Then we can manually forward traffic to the specific computer based on the request.
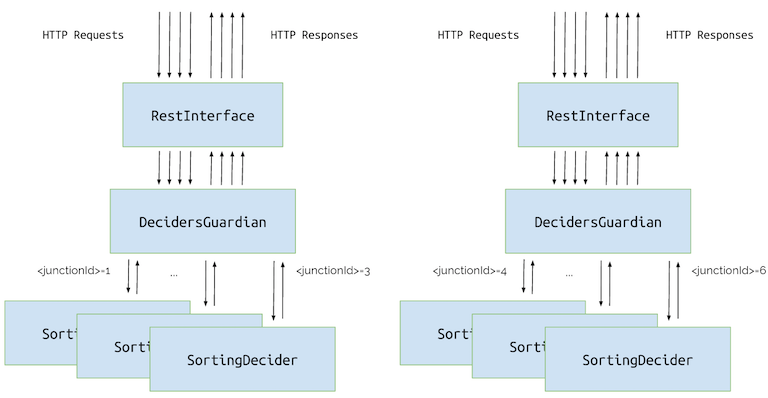
This technique is called manual scaling out. There are several drawbacks to this method. We need to maintain some business logic in the load balancer, we don’t have any redundancy and we need to adjust the whole setup each time we add a new junction or computer.
Furtunately, we don’t have to do all those things manually. Instead, we can use Akka Cluster extension that does just that (and even more). We will make our SortingDecider sharded. Instances of this actor will be automatically created based on junction id in the request. We will run two instances of our application (two nodes). Together they will form an Akka Cluster. All nodes in the cluster will be used by Sharding extension to create and migrate SortingDecider actors. We will be able to add and remove nodes as we go and Akka will automatically use those resources. Note that we don’t have to change any of the existing code in order to add sharding to the application. Additionally, we won’t need our DecidersGuardian because all of its responsibilities will be migrated to Akka’s ShardRegion.
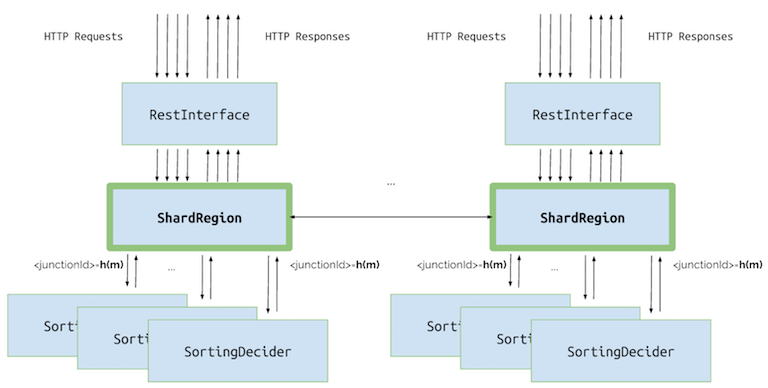
There are just two steps that we need to do in order to shard SortingDecider. First step is to create a companion object which defines props, shardName and two “hashing functions”:
extractShardId- this function defines a shard id based on incoming messages. Shards are just sets of our actors. One such a set can only be present on one node and Akka tries to have a similar number of shards on each available node. So, just by defining this function we can control how many shards our application supports. In our case, we only support 2 shards (see code below),extractEntityId- this function defines the entity id, that is the unique identifier of an actor that will process this message. Akka creates those actors automatically based on thePropswe have defined.
Both functions are called each time a ShardRegion receives a message. First a extractShardId function is called and it returns a shard id. Then Akka checks on which node this particular shard is kept. If this is another node, the message is forwarded there without additional work from our side. If this is the right node, extractEntityId function is evaluated. It returns entity id, which is an identifier of the particular actor. The message is forwarded to the actor and is processed there. If the actor doesn’t exist, it is automatically created. In our case we will have one actor per junction, so our extractEntityId function will return just junction id. This is how it looks in the code:
object SortingDecider {
def props = Props[SortingDecider]
def shardName = "sortingDecider"
val extractShardId: ExtractShardId = {
case WhereShouldIGo(junction, _) =>
(junction.id % 2).toString
}
val extractEntityId: ExtractEntityId = {
case m: WhereShouldIGo =>
(m.junction.id.toString, m)
}
}
class SortingDecider extends Actor {
// ...
}
Second step is to define our new App that will set up sharding based on the defined SortingDecider companion object. We will reuse all other actors we have created (including RestInterface).
object ShardedApp extends App {
val config = ConfigFactory.load("sharded")
val system = ActorSystem(config getString "clustering.cluster.name", config)
ClusterSharding(system).start(
typeName = SortingDecider.shardName,
entityProps = SortingDecider.props,
settings = ClusterShardingSettings(system),
extractShardId = SortingDecider.extractShardId,
extractEntityId = SortingDecider.extractEntityId)
val decider = ClusterSharding(system).shardRegion(SortingDecider.shardName)
system.actorOf(Props(classOf[RestInterface], decider, config getInt "application.exposed-port"))
}
Running one node
Let’s run just one node. The output of the performance test should be the same as in our manual solution. Let’s check whether this is true.
java -jar target/SortingDecider-1.0-SNAPSHOT-uber.jar
± % cat URLs.txt | parallel -j 5 'ab -ql -n 2000 -c 1 -k {}' | grep 'Requests per second'
Requests per second: 68.39 [#/sec] (mean)
Requests per second: 66.30 [#/sec] (mean)
Requests per second: 65.99 [#/sec] (mean)
Requests per second: 64.86 [#/sec] (mean)
Requests per second: 64.54 [#/sec] (mean)
As you see, we get a similar Requests per second values, because we still use just one JVM instance (= one computer). In this scenario, the application can only scale up.
Running two nodes
When we run the second node, it should automatically form a cluster with the first one and then use both nodes to create SortingDecider actors. This should also make our application process more requests. We use the same jar to run the second node, we just need to redefine exposed web interface port and Akka Cluster node port:
java -Dapplication.exposed-port=8081 -Dclustering.port=2552 -jar target/SortingDecider-1.0-SNAPSHOT-uber.jar
Before we execute our test, we also need to set up a simple round-robin based load balancer:
haproxy -f src/main/resources/haproxy.conf
This will run a server on port 8000 and just forward all the traffic to both 8080 (our first node) and 8081 (our second node) interchangeably. In our last test, we will use a different URLs file (shardedURLs.txt) to accomodate for this change.
± % cat shardedURLs.txt | parallel -j 5 'ab -ql -n 2000 -c 1 -k {}' | grep 'Requests per second'
Requests per second: 106.80 [#/sec] (mean)
Requests per second: 108.15 [#/sec] (mean)
Requests per second: 100.60 [#/sec] (mean)
Requests per second: 99.92 [#/sec] (mean)
Requests per second: 100.07 [#/sec] (mean)
As we see, we have improved the performance noticeably.
What you learnt
In this tutorial you learnt:
- how to create a web application using Akka and Spray,
- how to scale up application using actor model,
- how to scale out the application using Akka Cluster and Sharding extension,
- how to test the performance and scalability of the web application.
You can implement the same service and do the same performance analysis by checking out akka-sharding-example repository on GitHub. Each step in this blog post (see titles) has a corresponding branch in the repository to make your life easier. If you want to implement Step 4, please check out step3 branch and follow the blog section.
Bonus: Akka HTTP
There is also a bonus branch in the repository that uses Akka HTTP instead of Spray. This implementation behaves slightly different and I will blog about this in the near future.
